¿Qué es Screaming Frog y para qué sirve?
Screaming Frog es una herramienta que cualquier persona medianamente interesada en el mundo de las páginas web y su optimización debe conocer.
Lo que hace Screaming Frog es rastrear páginas web de forma sistemática y recoger información relevante. De esta forma podemos encontrar casi cualquier tipo de fallo On Site.
¿Quieres dejar tu web perfecta? ¡Pues vamos a ver en profundidad y con todo detalle cómo funciona esta poderosa herramienta!
Pero antes… Tienes que descargarte esta herramienta aquí para poder seguir este tutorial.
1.Configuración inicial
Al entrar a Screaming lo primero que vemos es una ventana donde pondremos la URL de nuestro sitio:
![]()
Cuando pinchemos en ‘Empezar’ comenzará a rastrear todo el sitio web; ahora bien, hay decenas de opciones y modos que debes controlar antes de comenzar ya que te permitirán optimizar mucho más el proceso y obtener únicamente la información que deseas.
En el menú de la parte superior pincha en ‘Configuración’ para desplegar el siguiente submenú:

1.1.Spider
La primera opción que se nos muestra es ‘Spider’ en la que vamos a poder configurar qué tipos de archivos queremos rastrear, qué información obtener y cómo.
Al pinchar sobre dicha opción se nos abrirá la siguiente ventana:
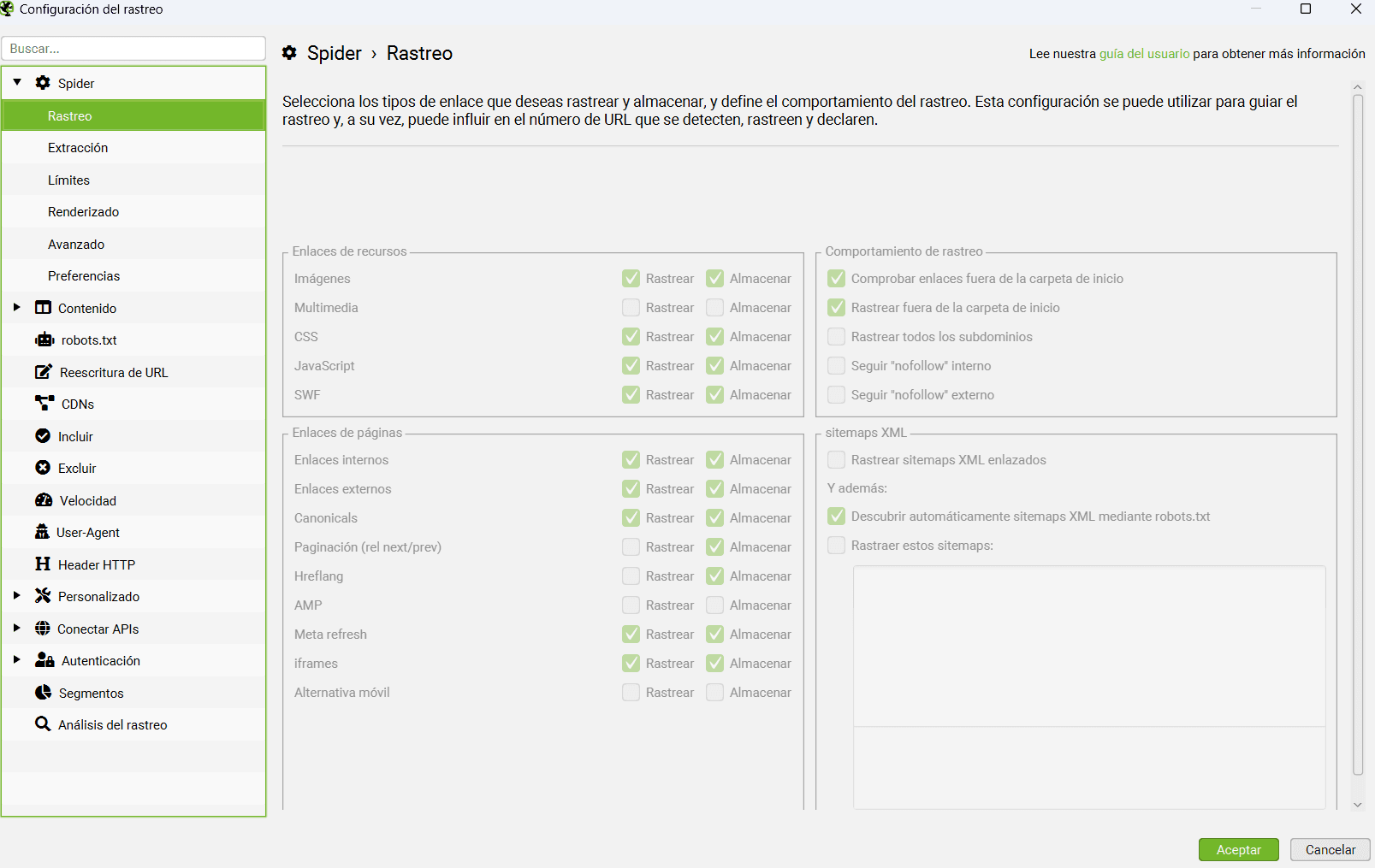
¿Qué rastrear en Screaming Frog?
Como podemos ver en la captura, Screaming Frog nos permite seleccionar el formato de archivos a rastrear. Podemos incluir/excluir las imágenes, CSS, archivos Javascript y SWF.
También podemos decirle que siga los enlaces internos o externos que estén marcados como ‘nofollow’ (aquí te dejo un artículo donde hablo sobre todo lo relacionado con los enlaces nofollow).
Con la opción de ‘Rastrear todos los subdominios’ le diremos a Screaming que si encuentra algún subdominio lo trate como enlace interno y no externo. Si por alguna razón quieres comenzar el rastreo por una URL que no sea la raíz, marca la opción ‘Rastrear fuera de la carpeta de Inicio’.
El resto de opciones sirven para rastrear las canonicals, el etiquetado de paginación Rel=’next’ y Rel=’prev’ así como las URLs marcadas con Hreflang.
Límites de rastreo
En la pestaña de «Límites» podemos establecer ciertos límites, muy útiles sobre todo si queremos acotar una web muy grande:
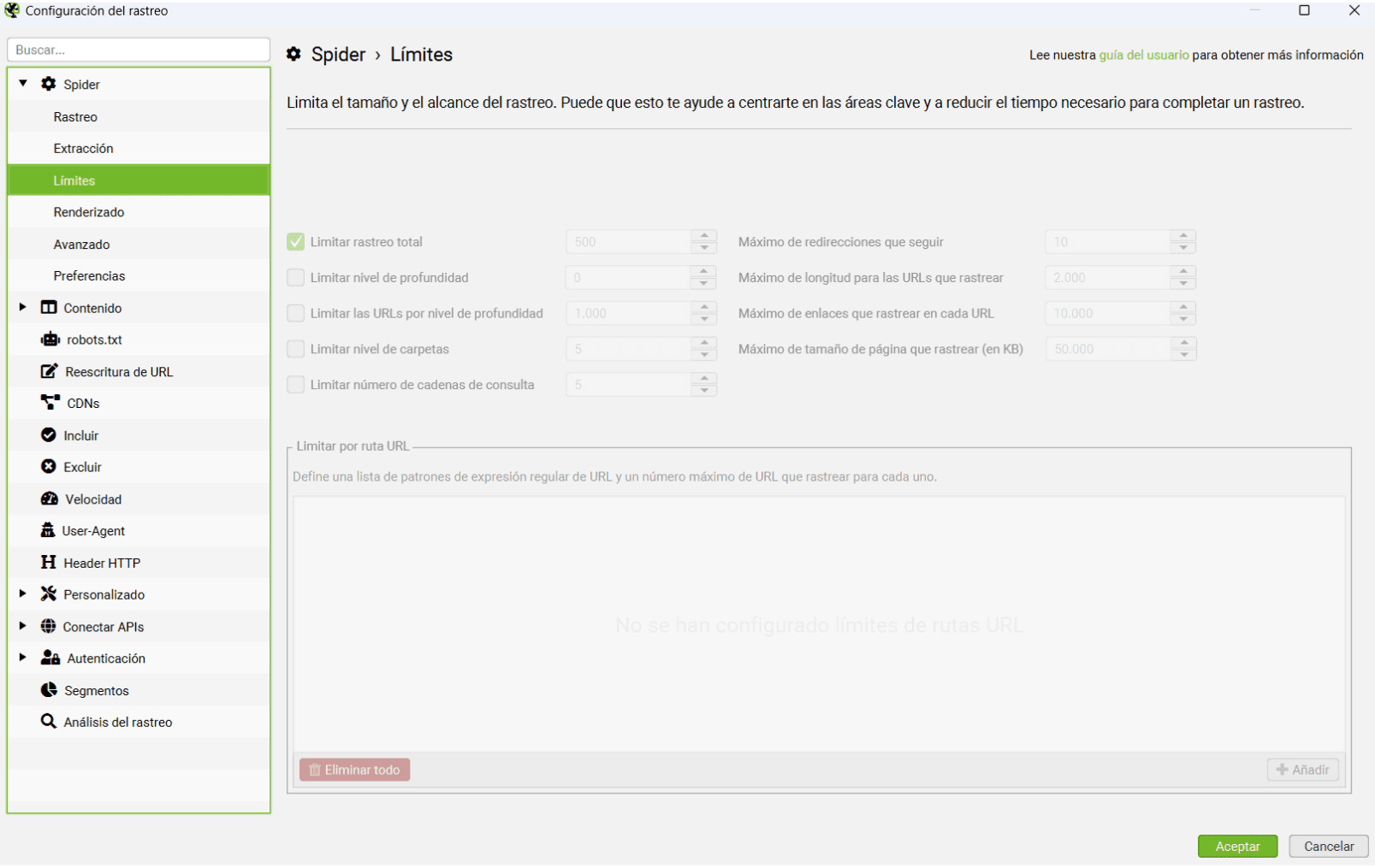
- Limit Search Total: Nos deja seleccionar un límite de URLs a rastrear. En un principio nos interesa analizar toda la web así que yo nunca suelo poner nada.
- Limit Search Depth: Establece el nivel de profundidad máximo. Nivel 1 sacaría los enlaces que encuentran a 1 clic desde la Home. Nivel 2 sacaría hasta los enlaces que están a 2 clics de la Home. Y así respectivamente.
- Limit Max URI Length to Crawl: Limita la longitud máxima (en caracteres) de las URLs a rastrear. Ej: Si ponemos 100, no rastreará las direcciones que tengan más de 100 letras en su sintaxis.
- Limit Max Folder Depth: Muy parecida a la segunda opción, pero esta vez limitamos a nivel de directorio. ¡Atención! Para Screaming nivel 0 no es la raíz del dominio sino un primer nivel de URL; es decir, si ponemos nivel 0 rastreará únicamente URLs que tengan 1 directorio (tipo luismvillanueva.com/seo). Si ponemos nivel 1 rastreará URLs que tengan como máximo 2 niveles de directorio (tipo luismvillanueva.com/seo/prueba
).
- Limit Number of Query Strings: Limita el número de parámetros, siempre que estos tengan un formato tipo ?x=. Ejemplo: dominio.com/zapatos?p=rojos tiene 1 parámetro. Dominio.com/zapatos?p=rojos_?
g=mujer tiene 2 parámetros.Muy útil si queremos excluir combinaciones de parámetros en tiendas online.
Renderizado
La siguiente pestaña ‘Rendering’ nos permite seleccionar entre 3 opciones que determinarán el modo de procesar el contenido de la página: procesando el Javascript o no.
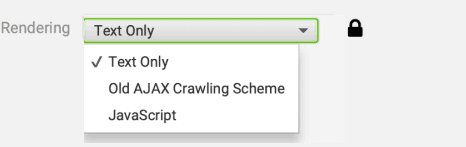
La opción que suele venir por defecto es ‘Old AJAX Crawling Scheme’ y básicamente lo que hace es emular un sistema de Google propuso en el año 2009 para rastrear contenido AJAX; aunque desde el año 2015 está obsoleto es lo que más se acerca al rastreo que hace actualmente.
Mi recomendación es dejar siempre esta opción, pero imagina que tu web tiene elementos Javascript que impiden el correcto rastreo por parte de Screaming. ¿Qué hacer? Seleccionamos la opción ‘Text Only’, con la cual únicamente rastrearemos el código HTML puro, obviando el Javascript.
Por último tenemos la tercera opción ‘Javascript’ la cual ejecuta este tipo de código si lo tenemos en la web e incluso nos sacará una captura de cómo se ve. Evidentemente esta opción es la más costosa para la herramienta así que seguramente te tarde bastante más tiempo en completar el proceso.
Al seleccionar ‘Javascript’ nos permite seleccionar el tiempo (en segundos) que se estará ejecutando el código AJAX hasta hacer la captura. Además podemos indicar el tamaño de la pantalla a la hora de realizar la captura.
Avanzado
Si con todo esto no tienes suficiente para personalizar a tu gusto el spider ¡vamos con las opciones avanzadas!
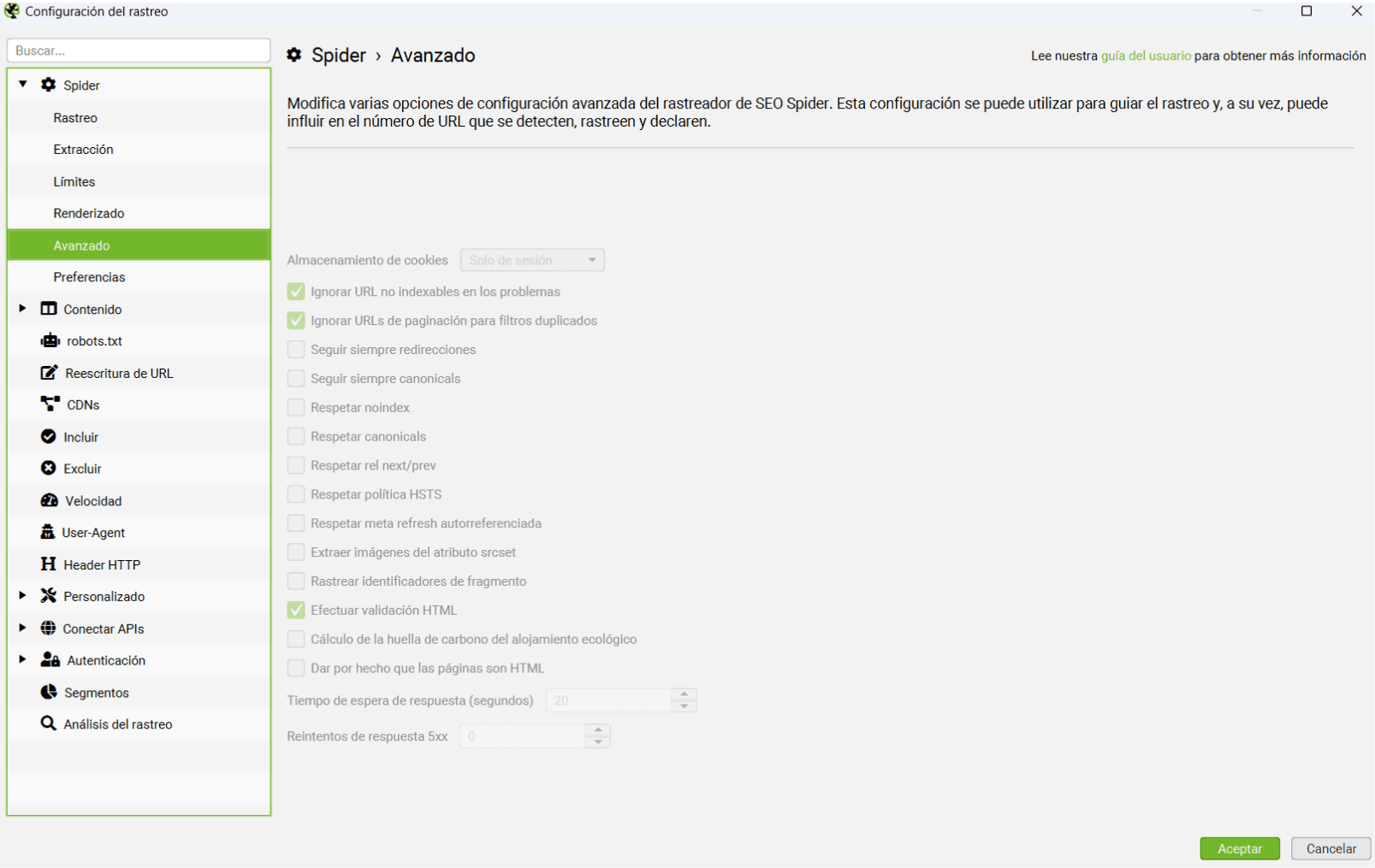
¿Has hecho una migración o sospechas que tienes cadenas de redirecciones?
Entonces selecciona ‘Seguir siempre redirecciones’. Screaming seguirá las redirecciones hasta la URL final.
Imagina que tienes una URL con un 301 que apunta a su vez a una URL que también tiene un 301. Con esta opción, una vez completado el proceso de rastreo podrás detectar y exportar estas cadenas desde la ventana de «Informes»-«Redirecciones» del menú principal.
Si marcamos ‘Respetar noindex’, ‘Respetar Canonical’ y ‘Restar Next/Prev’ no sacaremos en el informe final las URLs que tengan una etiqueta Noindex, una canonical hacia una URL que no sea sí misma o las etiquetas de paginación Next/Prev.
Al marcar ‘Extraer imágenes del atributo srcset’ Screaming sacará todas las imágenes que estén marcadas con el atributo srcset. Seguramente tu página web no cargue las fotografías de este modo ya que es un atributo CSS no muy común. Aquí puedes ver un ejemplo: https://webkit.org/
La casilla (‘Tiempo de espera de respuesta’) es muy interesante si la web que vamos a analizar es muy lenta, pues nos permite marcar el tiempo máximo (en segundos) que Screaming debe esperar a que cargue una URL. Por defecto están puestos 20 segundos; es decir, si pasan 20 segundos y la URL no ha cargado en el reporte nos dará que la URL tiene un código de respuesta 0 – ‘Connection TimeOut’.
Normalmente un portal no debería tardar ni de lejos tanto… pero si por X motivo necesitas esperar más segundos por URL aumenta esta cifra. Eso sí… te tocará esperar un buen rato si tiene muchas URLs.
Las 2 últimas casillas son muy sencillas: ‘5XX response retries’ indica las veces que Screaming intentará acceder a una URL con un código de respuesta tipo 5XX. Con ‘Max Redirects to Follow’ indicamos un máximo de redirecciones a seguir en una cadena.
Preferences
Y llegamos a la última pestaña de preferencias, donde podremos modificar a nuestro gusto las recomendaciones que por defecto señala Screaming Frog:
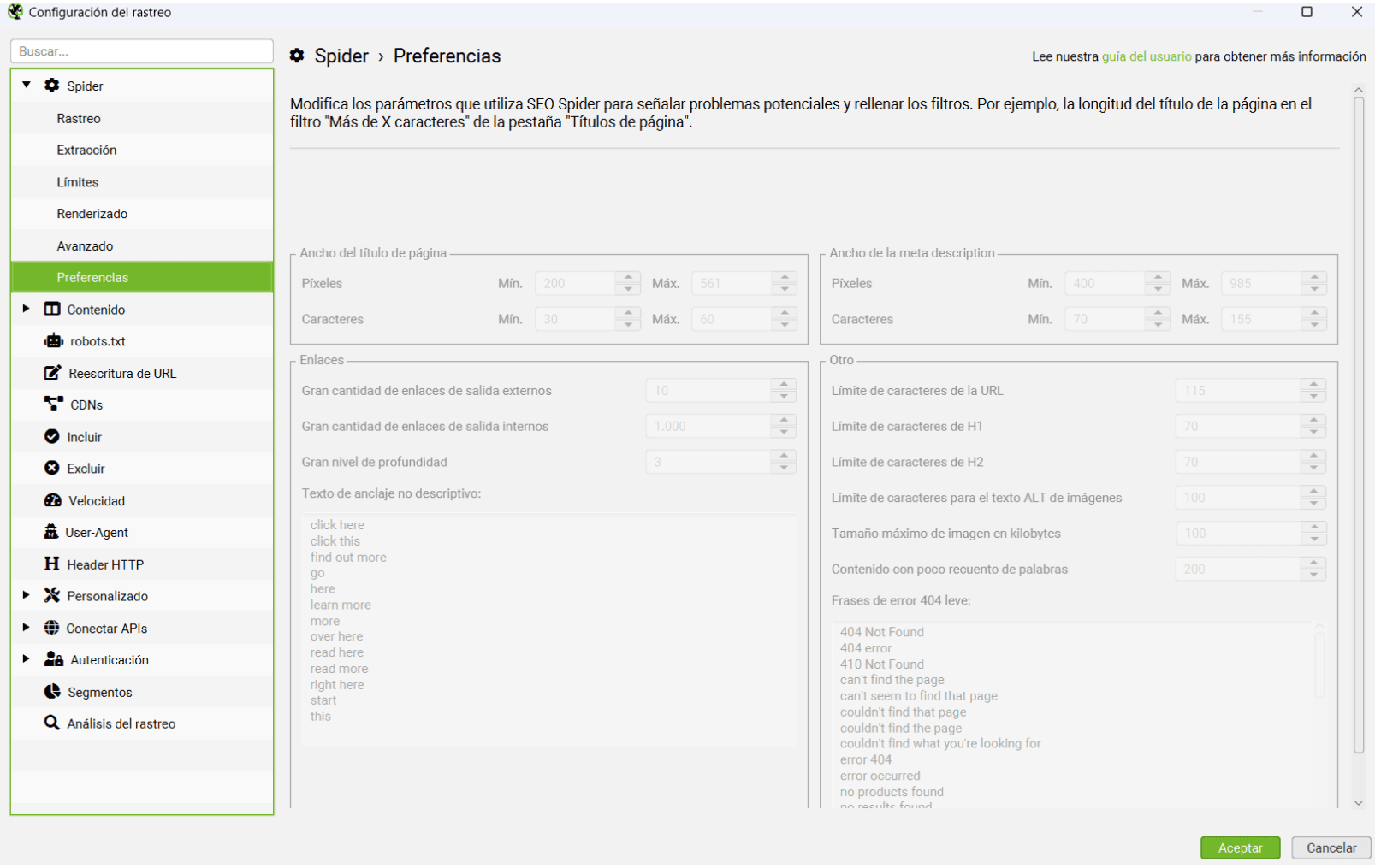
Como puedes observar, para Screaming la etiqueta title debería tener entre 30 y 60 caracteres. Todo lo que se salga de dichas directrices lo marcará como error.
Si tú sigues otro tipo de normativa y no quieres que en el reporte salga como error, modifica estos datos a tu gusto. Puedes cambiar el anchor en píxeles del title, description, el número máximo de caracteres que debería tener una URL, un H1, un H2, un atributo ALT o incluso el tamaño máximo (en Kilobytes) de las imágenes.
1.2.Robots.txt
Una vez configurado el Spider (ha costado eh…) nos vamos a la ventana de Robots.txt:
Tranquilo porque esto es mucho más sencillo que lo anterior. En «Ajustes» se nos mostrará la siguiente ventana:
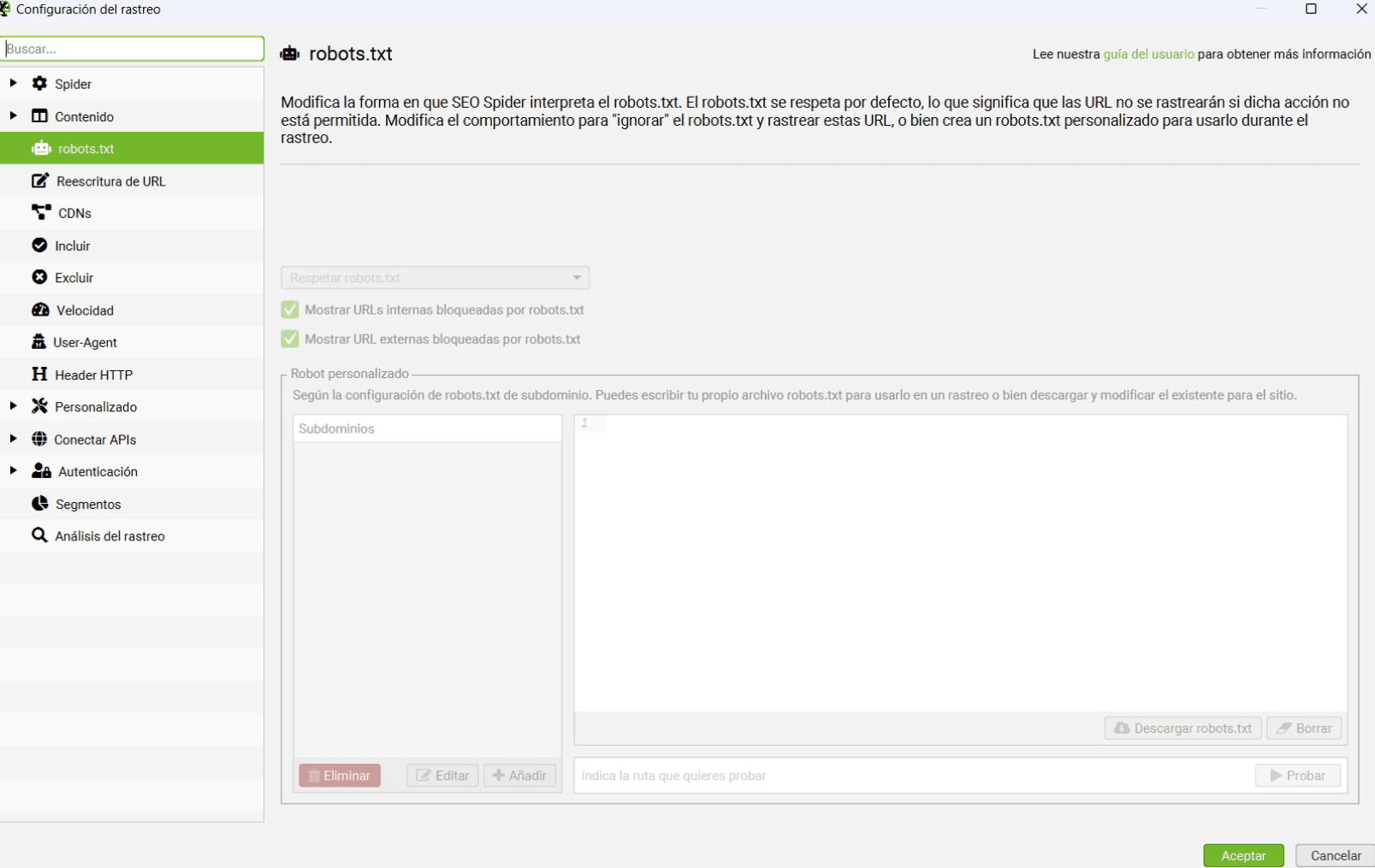
En la que podemos:
- Ignorar por completo el archivo robots.txt de nuestro portal, por lo que las URLs bloqueadas no se mostrarán como tal.
- Mostrar en el reporte final las URLs bloqueadas por robots.txt. Yo recomiendo siempre dejarla marcada para verificar que estás bloqueando las URLs deseadas, siempre estás a tiempo de borrarlas del reporte final después de comprobarlo.
- Mostrar URLs externas bloqueadas por robots.txt
Por otro lado, si lo que quieres es simular un robots.txt para hacer pruebas, pincha en la opción ‘Robot Personalizado’ y añade las líneas que desees. Eso sí, ten en cuenta que los cambios que hagas aquí no se realizarán en tu robots.txt real.
1.3. Reescritura de URL
Reescritura de URL o URL Rewriting es una función avanzada que nos permite modificar la sintaxis de las URLs y/o eliminar parámetros. Ten en cuenta que no elimina del reporte final las URLs con parámetros, sino que reescribe dichas URLs.
Para trabajar con esta opción tendremos que poner simplemente en la ventana inicial el parámetro a borrar. Sin los símbolos ‘?’ ni ‘=’; es decir, imaginad que queremos reescribir las paginaciones las cuales tienen una URL tipo luismvillanueva.com/blog?p=2. Únicamente pondríamos una ‘p’ en la ventana inicial:
Además podemos testear como quedaría en la pestaña ‘test’.
En la pestaña ‘Sustitución de Expresión Regular’ podemos utilizar expresiones regulares para reescribir las direcciones de una forma mucho más avanzada. Si te interesa puedes ver algunos ejemplos aquí: https://www.
1.4.Include y exclude
Dos de las funciones que más utilizo y a las que más utilidad les veo son ‘Incluir’ y ‘Excluir’. Gracias a ellas podemos hacer un rastreo segmentado; cuando estamos frente a un portal extremadamente grande (miles o millones de URLs) Screaming no puede hacer frente a tal cantidad de direcciones y se bloqueará llegados a cierto punto.
Por lo tanto, estas opciones son simplemente vitales para webs grandes y es muy aconsejable que sepas bien utilizarlas y cómo funcionan.
Ambas tienen la misma apariencia: una ventana donde iremos añadiendo los parámetros o carpetas (una por línea) a incluir/excluir:
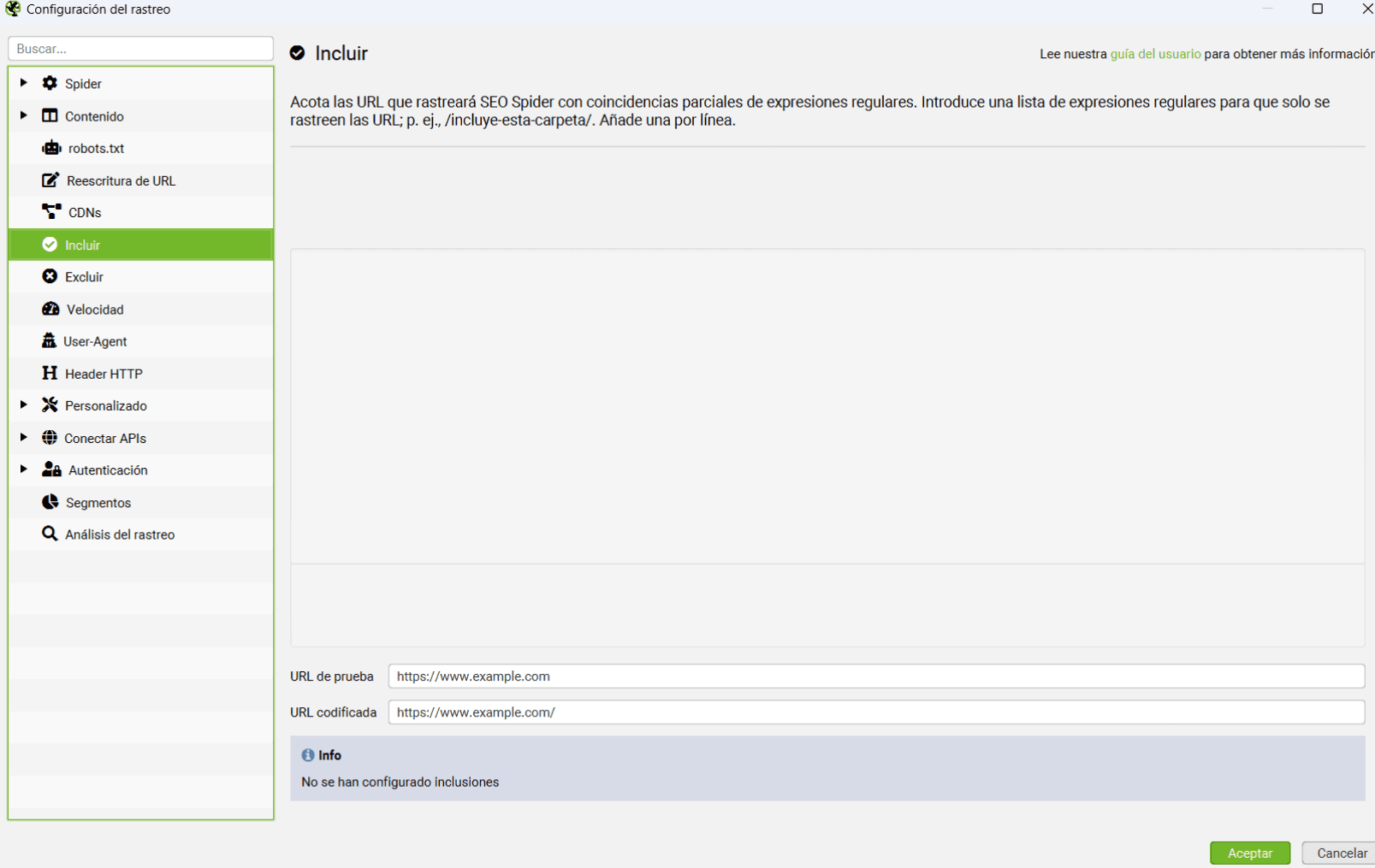
Utilizaremos la expresión regular ‘.*’ (sin las comillas) antes o después del parámetro para indicar que cualquier elemento que esté en dichas posiciones debe ser excluido/incluido.
Con un ejemplo queda más claro: Si en un rastreo queremos excluir todos los filtros que contengan ‘?page=’, en la ventana de Exclude añadiremos .*?page=.*. Así, todas estas URLs no serán rastreadas:
- com/?page=23
- luismvillanueva.com/blog?page=
22 - com/blog?color=gris?page=23
Puedes ver más expresiones regulares aquí: https://www.
Por último es muy importante que sepas que si excluyes una URL Screaming no la rastreará en absoluto, no la tendrá en cuenta ni la sacará en el reporte final, por lo que si dicha URL contiene enlaces internos hacia otras URLs estos no serán seguidos. Si una URL solo es accesible a través de una dirección que has excluido, jamás llegará a ella.
1.5.Speed
Cuando realices un rastreo con Screaming Frog este irá analizando progresivamente todas las direcciones del portal a una velocidad proporcional a la carga de la web.
En ocasiones puede ocurrir que una web lenta o que no soporte un gran volumen de usuarios simultáneos se vaya todavía más lenta o incluso se caiga cuando le pasemos Screaming Frog. En estos casos puede sernos de gran utilidad la opción ‘Speed’ o ‘Velocidad’:
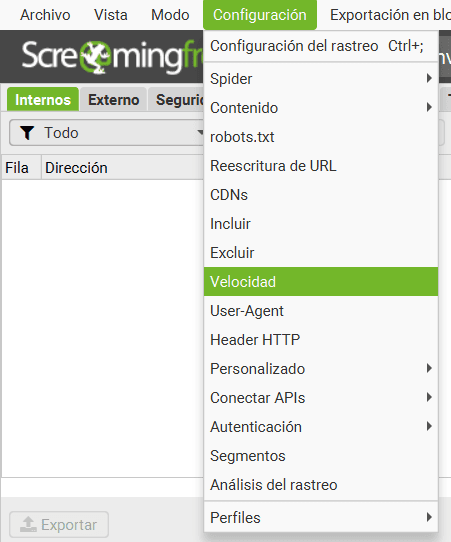
Mediante la cual controlamos manualmente la velocidad a la que Screaming rastrea un sitio:
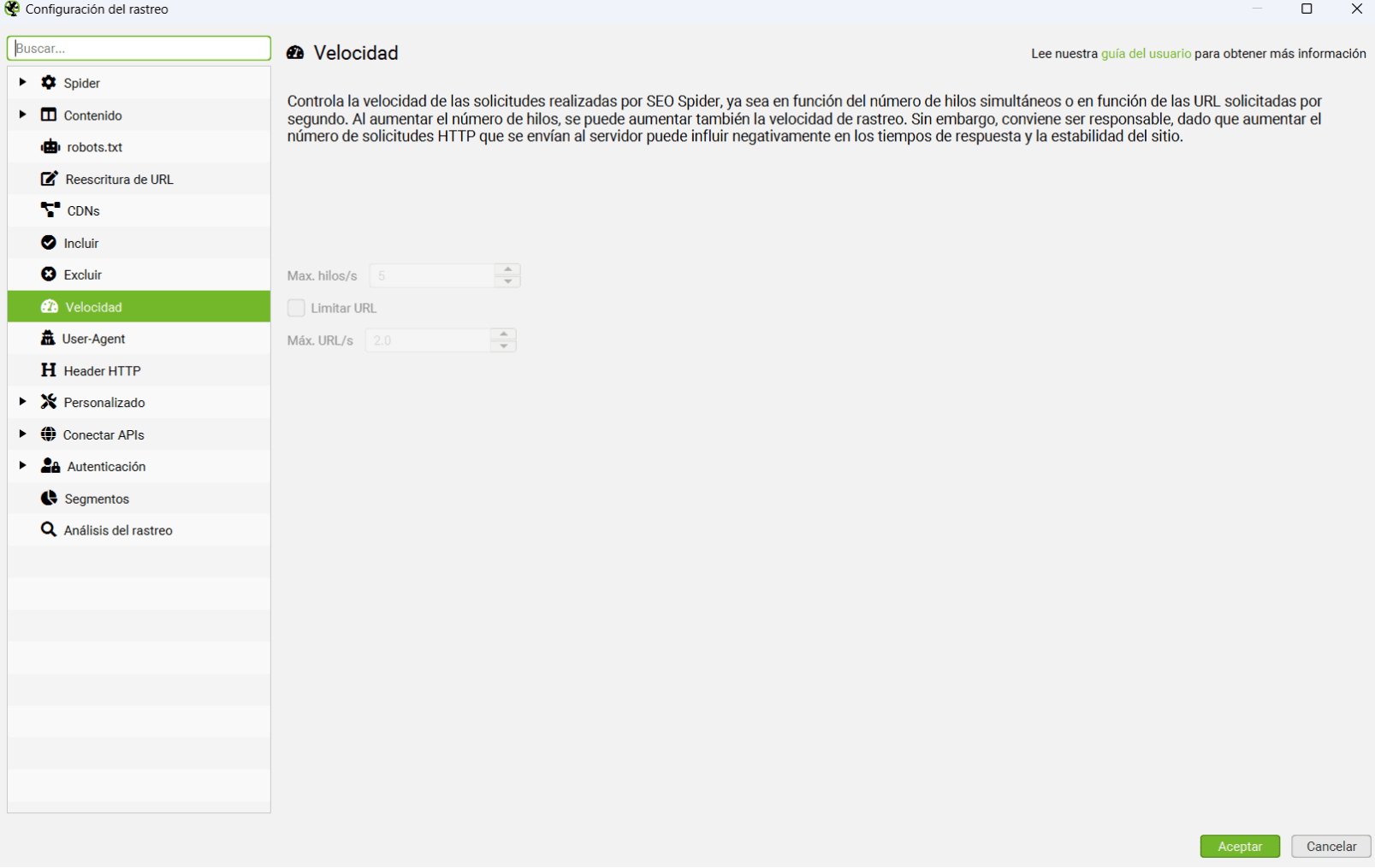
Con ‘Max Hilos’ indicamos el número máximo de tareas (o arañas en este caso) simultáneas que trabajan. Con 5 suele ser más que suficiente, este dato prácticamente nunca suelo tocarlo.
Si pinchamos en ‘Max URI/s’ nos dejará modificar las URLs máximas por segundo a rastrear. Si tienes un sitio que carga como las tortugas o que se cae fácilmente te recomiendo dejarlo entre 2 y 5 URLs por segundo.
1.6.HTTP Header
En la pestaña Header HTTP podemos cambiar el User-Agent para que al realizar el rastreo la web responda de una manera u otra.
Así, podemos simular que somos GoogleBot, GoogleBot Smartphone o Bingbot entre otros. Por defecto estará seleccionado el propio User-Agent de Screaming Frog; si al analizar un portal no avanza la progresión (no rastrea ni una URL) puede ser que el servidor de la web tenga bloqueado Screaming o simplemente que no responda bien frente a este User-Agent. Prueba a cambiarlo por Googlebot.
1.7.Búsquedas personalizadas y extracción de datos específicos
Si estás auditando un sitio muchas veces necesitarás sacar un determinado conjunto de URLs que contienen X elemento: las que tienen el código de Analytics puesto, en las que se menciona X keyword, etc…
Gracias a la función ‘Búsqueda personalizada’ podemos separar las URLs que contengan (o que no contengan) en su código fuente lo que nosotros deseemos.
Una vez termine de rastrear todas las URLs podremos ver en la pestaña ‘Personalizado’ las páginas donde ha encontrado lo indicado.
¿Y si queremos extraer datos? ¡También se puede! Con la opción ‘Extracción Personalizada’ podemos obtener directamente el contenido que hay dentro de una etiqueta HTML.
Tenemos diferentes maneras de hacerlo, utilizando expresiones regulares, la ruta Xpath o la ruta CSSPath; dependiendo del elemento que quieras extraer te resultará más fácil hacerlo de una manera u otra.
Si no te ha quedado claro cuál es la finalidad de esta función te pongo ejemplos: podríamos sacar todos los nombres de producto de una tienda online o todos los términos que tiene cada URL en las migas de pan.
Vamos ahora con un ejemplo real: en mi blog antes tenía el dato estimado de los minutos que tardarás en leer un post (ahora ya no pero me vale como ejemplo).
En Google Chrome inspecciono elemento para ver el código fuente y me copio el Xpath.
Si ahora lo pego en la función que acabamos de comentar, scrapeo mi sitio y me voy a la pestaña ‘Personalizado’ – ‘Extracción’ me aparecen al lado de las URLs el número de minutos estimados de lectura.
El límite está en tu imaginación ¡puedes extraer la información que necesites!
2.Modo
En el menú principal también podemos cambiar el modo de rastreo:

- Spider: Screaming actuará como una araña, saltando de URL en URL siguiendo los enlaces internos. Empezará a rastrear por la dirección que le indiquemos:
- Lista: Con esta opción activada Screaming analizará un listado de URLs que nosotros le indicaremos manualmente.
Con el modo ‘Lista’ se pueden hacer cosas interesantes como por ejemplo analizar todas las direcciones de un Sitemap y detectar las que devuelven errores 404, 301, etc…
3. Analizando la información rastreada
Ahora sí que sí, cuando tengas todo configurado ya puedes pinchar en ‘Start’ y comenzará a analizar tu sitio. Cuantas más páginas tenga tu web más tardará en completar todo el proceso.
Cuando llegue al 100% tendrás diferentes paneles con una cantidad de información asombrosa. Para navegar por todos estos datos bien puedes utilizar las pestañas de la parte superior:
![]()
O bien desplazarte por el recuadro de la derecha, el cual incluye subsecciones para que puedas ir directamente a lo que te interesa.
En el panel central se encuentra la información obtenida y dependiendo de la pestaña en la que estés será una u otra:
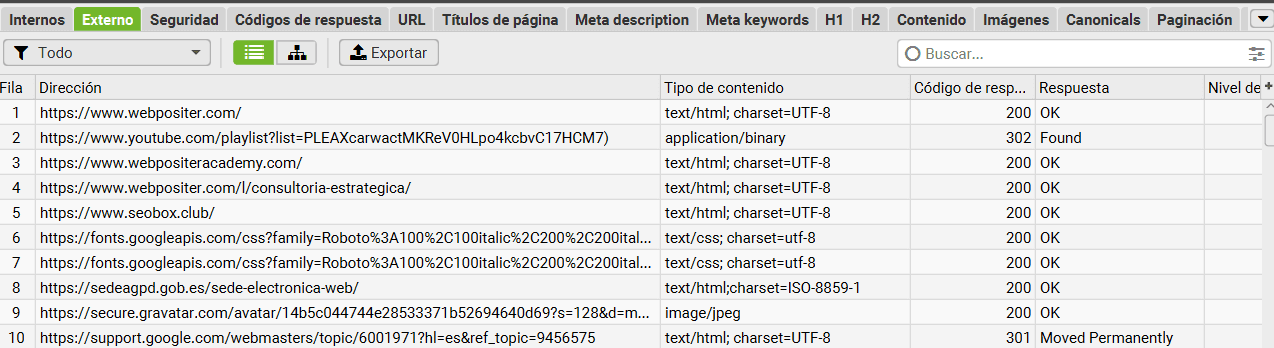
3.1- Internal: Analizando las URLs del proyecto
Aunque en la imagen anterior yo te he mostrado la pestaña «Externo», por defecto estaremos en la pestaña «Interno» donde se mostrarán todas las URLs que Screaming ha encontrado junto con los siguientes datos:
- Status y Status Code: Nos indican el código de respuesta el cual puede ser 200, 301, 404, etc…
- Canonical
- Etiqueta meta robots
- Title
- Description
- Encabezados H1 y H2
- Tamaño de la página (en bytes)
- Número de palabras
- Text Ratio: proporción entre contenido y código
- Level: Nivel de profundidad, la Home estará a nivel 0, una URL que está a un clic de la Home estará nivel 1, etc…
- Inlinks: Cantidad de enlaces entrantes internos que tiene dicha URL
- Outlinks: Cantidad de enlaces internos salientes hacia otras partes de la web
- External Outlinks: Número de enlaces externos salientes desde esa URL
- Hash: Es un código identificativo único generado a partir del código fuente, es decir, si dos páginas tienen exactamente el mismo código el hash será idéntico. Es un valor a tener en cuenta para sacar contenido duplicado.
- Response time: tiempo en segundos que tarda la página en cargar.
Además de todo esto podemos filtrar rápidamente por tipo de contenido ya que en la barra de la derecha, dentro de la categoría ‘Internal’ vemos lo siguiente:
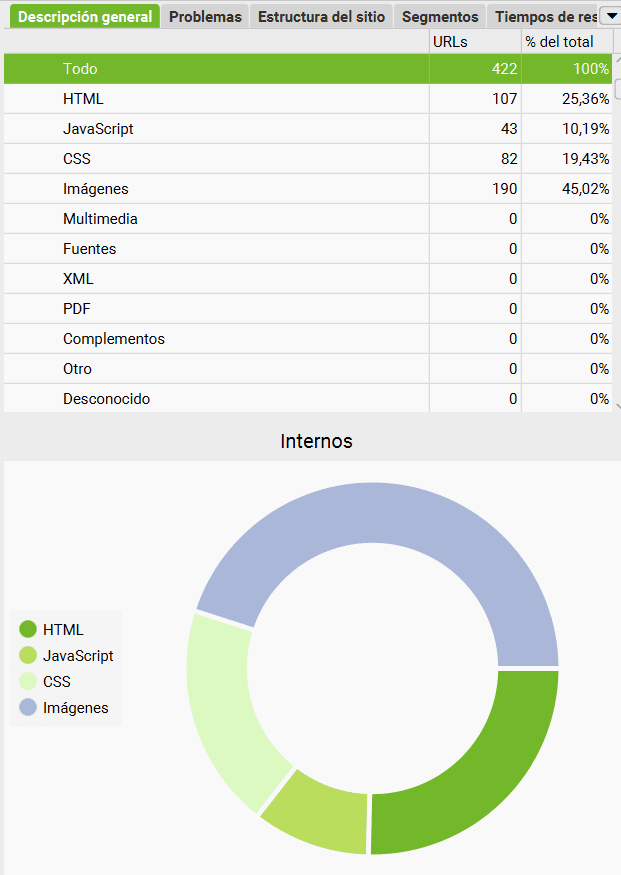
Al pinchar en cualquiera de los formatos el panel central se actualizará mostrando únicamente las URLs que coincidan con el valor seleccionado.
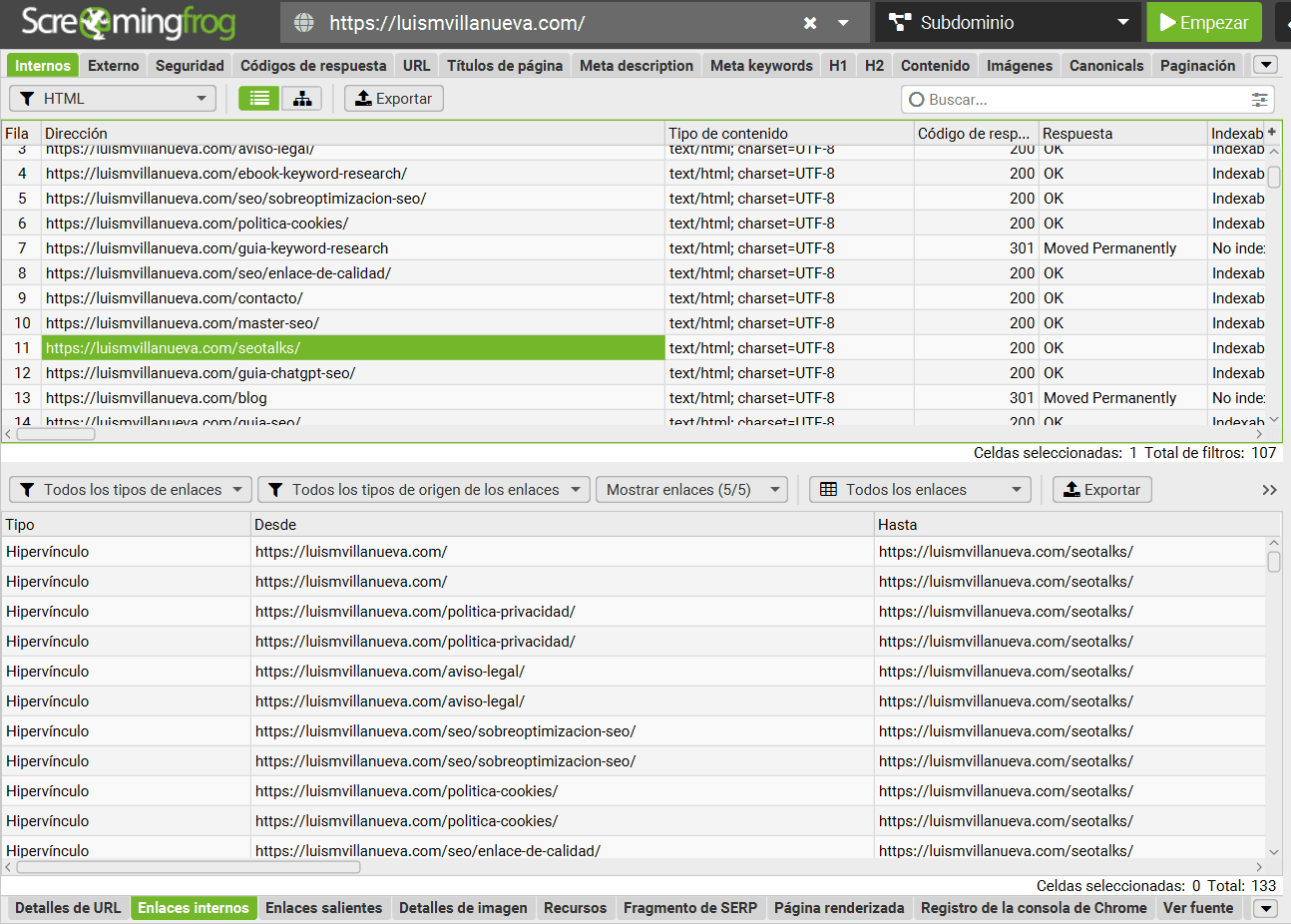
¿Cómo obtener los enlaces internos entrantes y los enlaces internos salientes de una URL en concreto?
Si pinchas encima de una dirección (en el panel central) verás en la parte inferior una ventana con diferentes pestañas. Allí podrás encontrar tanto los Inlinks como los Outlinks de esa página:
Si lo que quieres es exportar directamente esta información a un Excel, pincha con el botón derecho sobre la URL que desees; verás un desplegable como el siguiente:
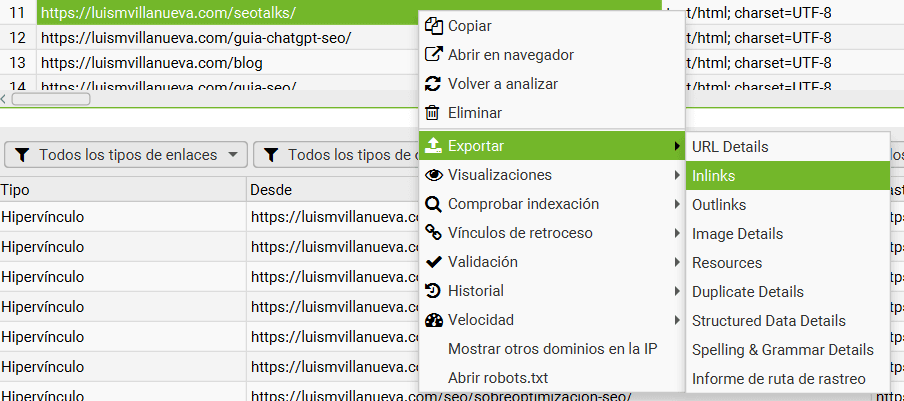
Donde podrás guardar los Inlinks y Outlinks (ojo, de esa URL en concreto) así como checkear otros elementos muy interesantes como la caché, si está indexada o no, verla en archive.org,etc…
3.2- External: Analizando los enlaces salientes externos
Pasamos a la siguiente pestaña ‘Externo’ donde podremos visualizar todos los enlaces externos que tenemos en nuestro sitio, es decir, todos los links que hemos puesto a otros dominios.
Este panel es exactamente igual que el ‘Interno’ ya que tiene los mismos filtros y las mismas columnas de información.
3.4- Analizando códigos de respuesta
En la cuarta pestaña ‘Códigos de Respuesta’ aparecerán todas las direcciones del portal y podremos filtrarlas según el código de respuesta que den:
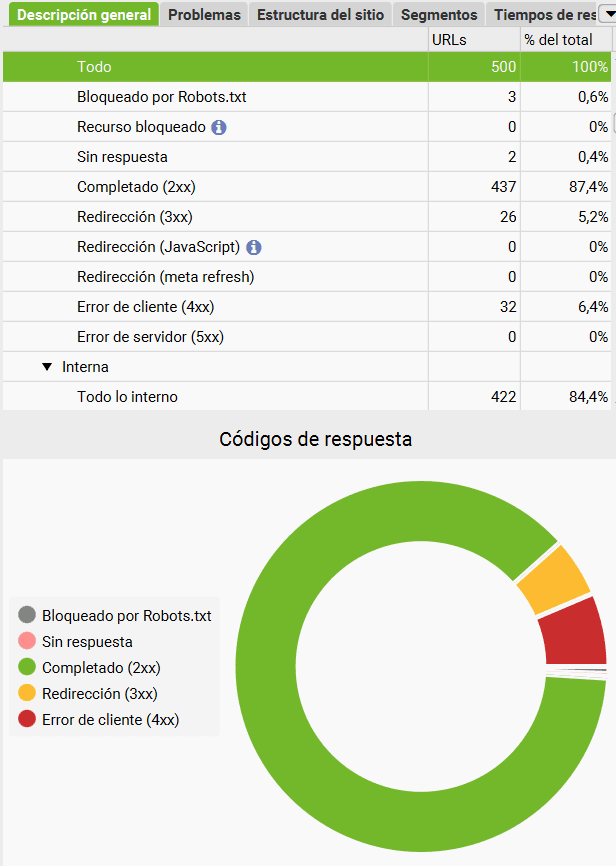
Analiza todo lo que no tenga un código de respuesta 200 y toma las decisiones adecuadas según la necesidad.
- Comprueba que las URLs bloqueadas por robots.txt son justo las que querías
- Comprueba que no tienes ninguna página ‘No response’
- Revisa si todas las redirecciones que tienes son estrictamente necesarias
- Comprueba que no tienes páginas rotas, que devuelvan un 404
3.5- URL: Analiza la sintaxis de tus URLs
La siguiente ventana se encarga de darte información acerca de tus URLs, concretamente de cómo están escritas. Los filtros que encontrarás en el panel derecho son los siguientes (te pongo los nombres en inglés por si lo tienes configurado en este idioma):
- Non ASCII Characters: Direcciones que contienen caracteres extraños, no pertenecientes a la codificación ASCII.
- Underscores: Detecta URLs que incluyan barra baja.
- Uppercase: Detecta URLs que incluyan mayúsculas.
- Duplicate: Detecta URLs con el mismo hash (comentado anteriormente). Es decir, detecta páginas idénticas.
- Parameters: direcciones que contienen parámetros. Es tremendamente útil para ver de un vistazo todos los que tienes y revisar si están bloqueados por robots, tienen noindex, etc…
- Over 115 Characters: Muestra URLs demasiado largas, con más de 115 caracteres. Siempre son recomendables direcciones sencillas y cortas.
3.6- Titles y descriptions
Ambos paneles tienen exactamente el mismo tipo de filtros. En un solo clic podemos ver todas las páginas a las que el title o la description:
- Están vacíos.
- Tienen duplicidad con otras páginas internas.
- Son demasiado largos y por lo tanto en los resultados de búsqueda no se visualizan enteros.
- Son demasiado cortos.
- Son exactamente igual que el encabezado H1.
- Son múltiples, es decir, en una sola dirección tenemos varios title o varias description lo cual estaría mal.
3.7- Encabezados e imágenes
H1, H2 e Images son 3 de las pestañas más simples y sencillas.
Podemos sacar rápidamente las páginas que no tengan encabezados H1 o H2, que se repitan en varias páginas, que sean demasiado largos o que dentro de una misma URL estén repetidos (no necesariamente con el mismo texto).
En los filtros de imagen podemos seleccionar las que pesan más de 100 kb, las que no tienen un atributo ALT o las que lo tienen pero es demasiado largo. Son 3 elementos que solemos descuidar bastante a la hora de realizar SEO pero que pueden ayudarnos mucho a mejorar el On Site de nuestro portal.
3.8- Directives
Uno de los últimos paneles pero no por ello menos relevante es el de las directivas o ‘Directives’ en el que se muestran datos tan valiosos como:
- Canonical: URLs que contienen una etiqueta canonical ya sea hacia sí mismas o hacia otra URL
- Canonicalizadas: URLs que contienen una etiqueta canonical que apunta hacia otra URL diferente.
- Next/Prev: Contienen estas etiquetas de paginación.
- Index / Noindex: Contienen dicha etiqueta la cual indica a Google si deseamos que se indexe o no.
- Follow / Nofollow: Si contienen esta meta tag el cual indica a Google que siga o no los hipervínculos que contiene dicha URL.
Como verás hay otros filtros pero de menor importancia ya que analizan metas bastante obsoletas.
3.9- Arquitectura y niveles de profundidad
Aunque está algo oculto, si te fijas bien en la esquina superior derecha justo encima de los filtros que acabamos de comentar verás una pestaña en la que pone ‘Estructura del Sitio’:
![]()
Al acceder a ella veremos una gráfica muy ilustrativa con la distribución de niveles de profundidad que tienen nuestras URLs:
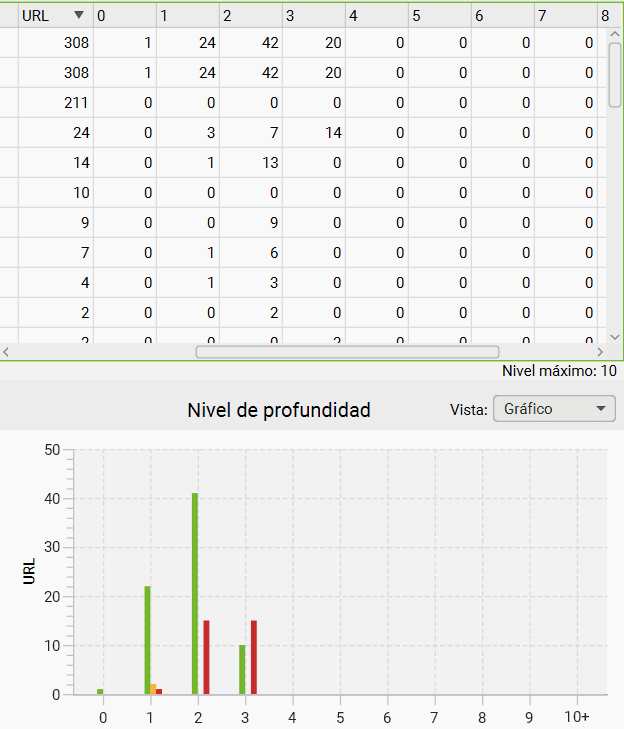
En el ejemplo podemos observar que la mayor parte de las páginas están a un segundo nivel de clic desde la Home. Es importante no tener demasiadas URLs en niveles muy lejanos ya que al bot de Google le costará más llegar a ellas.
4. Exportar información (reportes)
Como has podido comprobar Screaming Frog es un software tremendamente poderoso que cualquier SEO debería manejar a la perfección.
Es tal la cantidad de datos e información que nos arroja que en muchas ocasiones lo más recomendable es exportar un pequeño segmento y seguir trabajando en Excel.
Para ello, Screaming tiene en el menú principal una sección ‘Exportación en bloque’ o ‘Bulk Esport’ que nos facilita muchísimo esta tarea.
Entre todas las opciones que permite las que más interesantes me parecen y más utilizo son:
- All Inlinks y All Outlinks: Exporta todas las URLs del sitio junto con todos sus enlaces internos entrantes y salientes respectivamente.
- Response Codes: Exporta conjuntos de URLs según el código de respuesta que tengan. Lo bueno es que añade por cada dirección las páginas donde se encuentra incrustado dicho enlace. Es decir, podremos saber por ejemplo si tenemos una redirección 301 dónde encontrarla dentro de nuestro portal (en qué artículo o en qué texto está).